一、写在前面
声研 · VocalLabs 是一款领先的 AI 语音合成平台,能够将文字快速转化为自然流畅的语音。它不仅在英文语音上表现出色,对中文及其他多语言的处理也相对稳定,能够准确体现语调、停顿和情绪,使生成的声音更接近真人。
这款平台的核心优势主要体现在以下几个方面:
-
语音拟真度高:声音流畅自然,能够传达喜怒哀乐等情绪细节,让配音更具感染力。
-
多语言支持:除了英文和中文,还覆盖日文等多种语言,适合面向全球的内容创作。
-
情感表达丰富:根据文本语境调整语调和情绪,使声音更生动自然。
适合多种用户群体
自媒体运营者:在 抖音、B站 等平台发布内容时,需要自然的人物配音。
播客和有声小说创作者:需要多种语音风格和情绪表达以提升内容表现力。
企业和教育机构:制作在线课程、培训视频或广告旁白时,追求高质量配音。
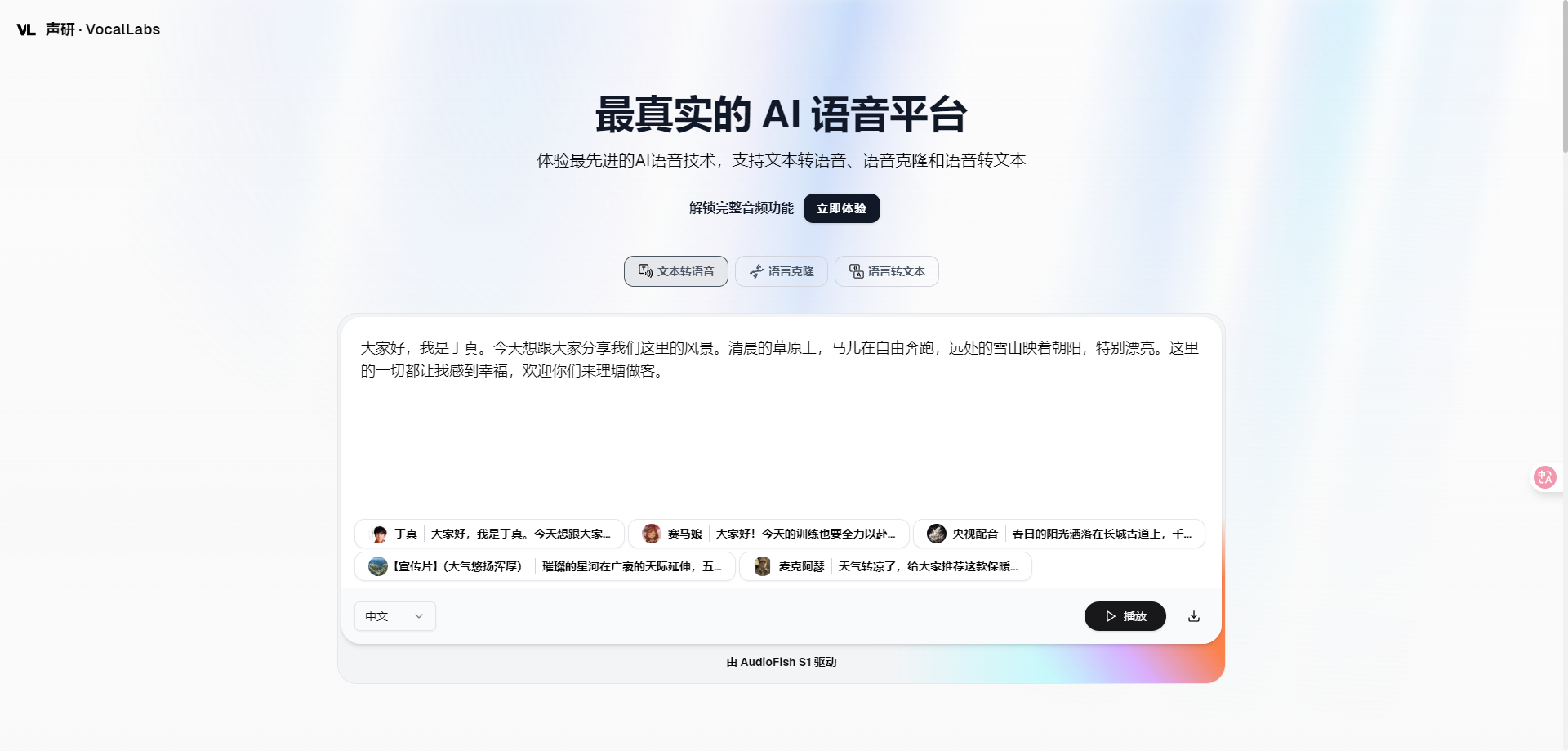
二、🚀网站核心功能
1 文本转语音
将文字实时转换为自然流畅的语音,支持多语言(如英语、中文、西班牙语等),并提供多种音色选择,一键生成自然流畅的语音,几乎听不出是AI。
1️⃣ 打开网站 👉 https://app.vocallabs.cn/audio
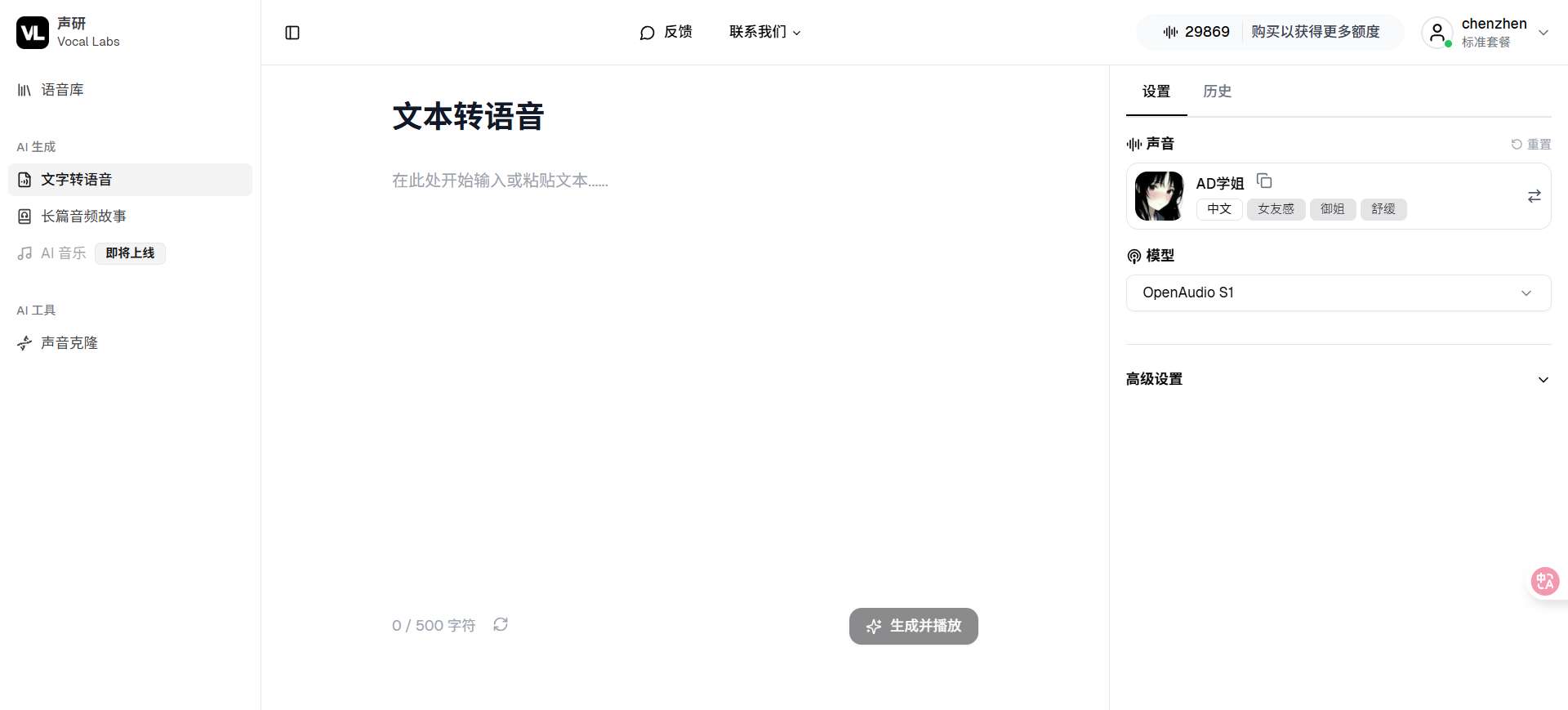
2️⃣ 输入你想说的内容
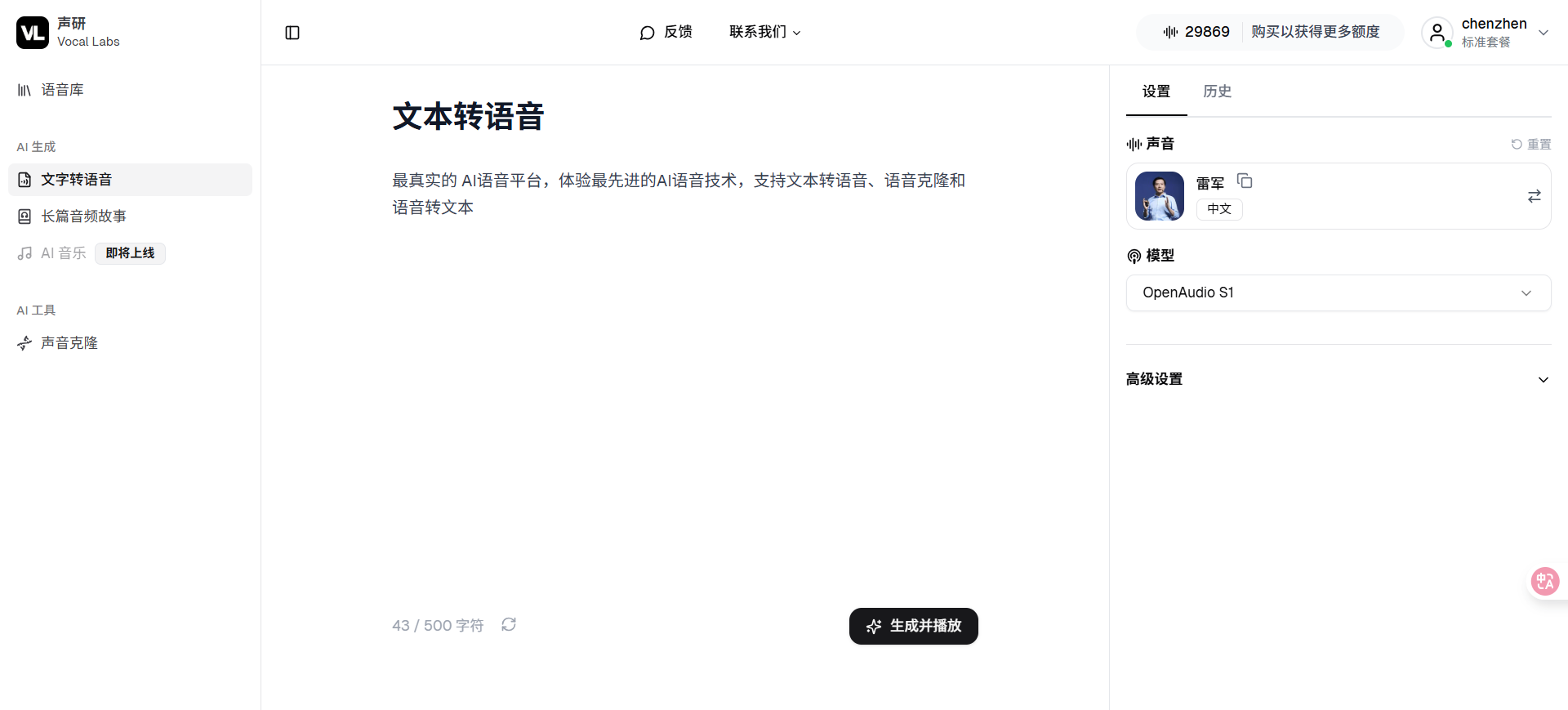
3️⃣ 在右边选择声音模型、速度、音量等
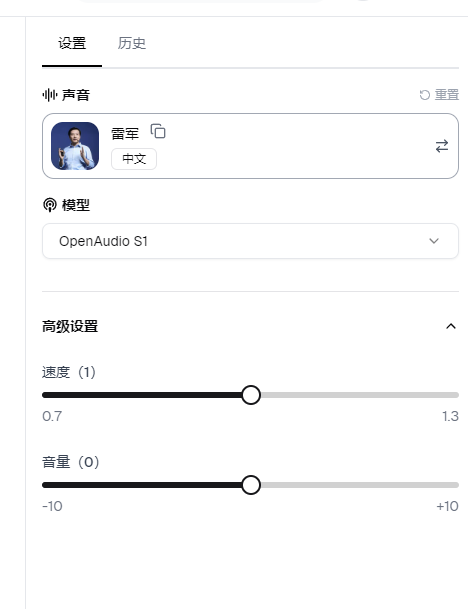
4️⃣ 点击“生成”按钮,几秒钟后就能试听!想保存就直接下载成 mp3。
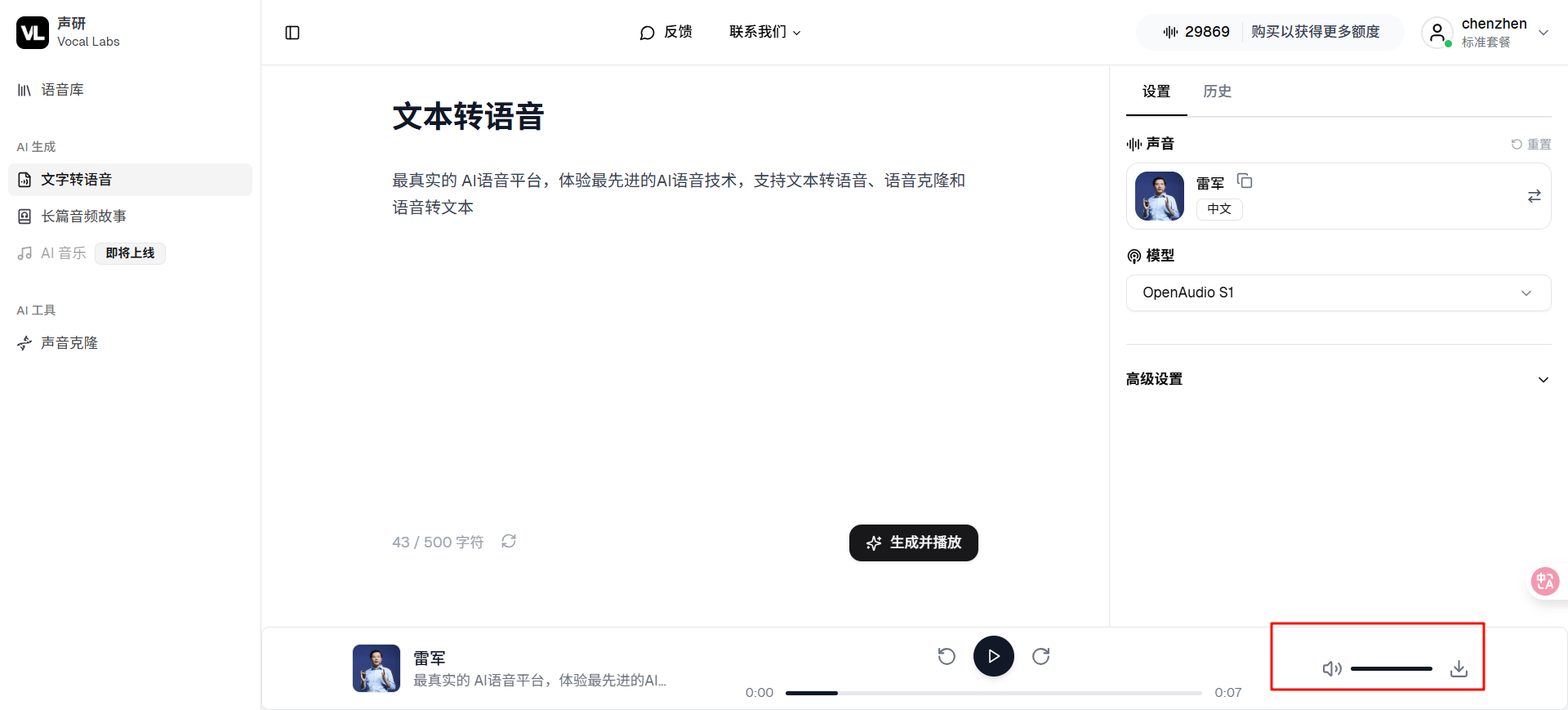
2. 语音克隆
仅需最低10秒左右的音频,就可以直接克隆任何一个人的声音,完美复刻他的说话方式、他的音色,甚至连他的情绪都复刻过来。
尽管很多的大厂的语音TTS能力已经很强大了,微软、OpenAI、Google这些巨头的语音模型早就能做到几乎“以假乱真”,但是这些大厂有一个问题,就是公司体量实在太大了,微软的声音克隆门槛极高,需要数小时的录音数据+高额费用。
至于那些开源的TTS,说实话,效果都挺差强人意,比如 Tortoise 奇慢无比,比如 bark 下限和稳定性太差,都难堪大用。
而声研 · VocalLabs,只需要10秒到1分钟的音频,就可以克隆出自然的AI声音了。效果还出奇的好。
🎯 声研 官网入口 : https://app.vocallabs.cn/
毕竟在现在这个AI时代,AI语音已经成了最为重要的环节之一。内容全球化翻译、智能配音、数字人与机器人等,都有超强的应用。换句话说,没有强TTS在背后支持,那些视频和数字人,各个都是恐怖谷效应拉满假到不行的哑巴。
而声研的使用上,更是突出一个简单和有手就行。
1️⃣ 先准备10秒到1分钟的声音样本,推荐时长30s,不需要超过1分半钟,对质量几乎没有任何意义了。你可以多个声音样本,但是每个不要超过20M。这块一定要注意,声音样本的质量跟你后面生成的质量息息相关,里面不要有任何杂音,越干净、越纯粹越好。
2️⃣ 然后进入声研的主页,登录后进入这个语音克隆的页面。这个页面就可以去做声音的克隆了。
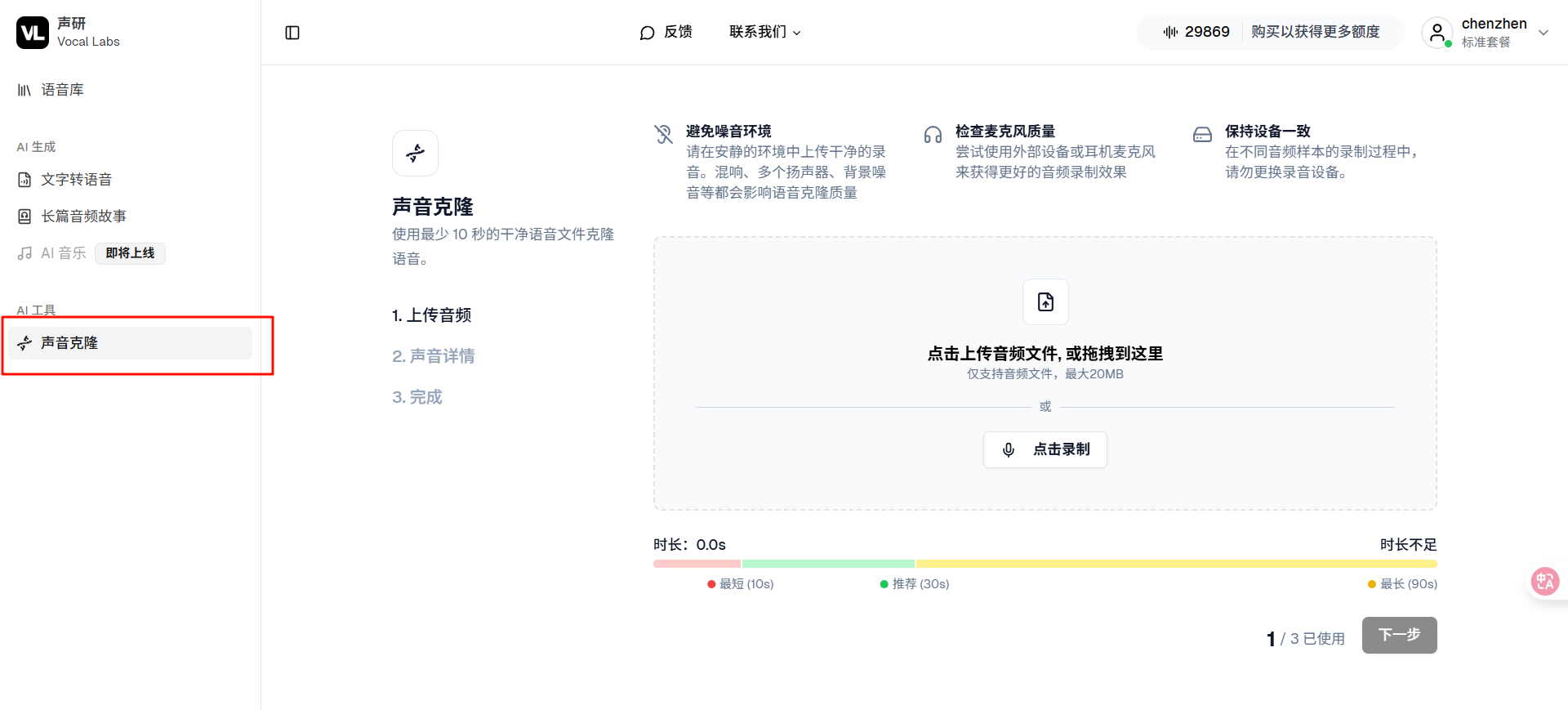
3️⃣ 把声音样本拖进去就行,然后下一步。
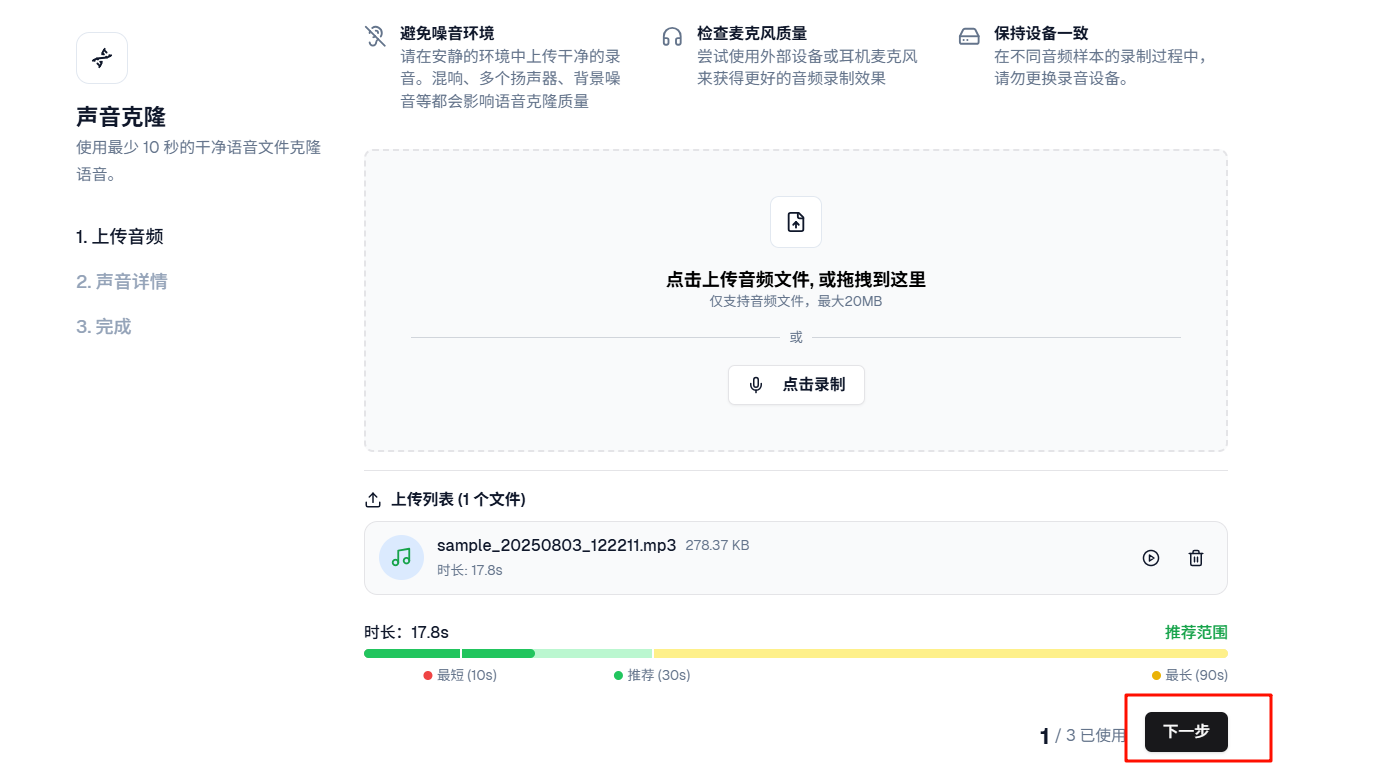
4️⃣ 上传封面图,填写声音名称,标签和描述啥的不用填,然后创建声音。
5️⃣ 大概只需要二十几秒钟吧,模型就OK了,速度出奇的快。点击查看所有声音,可以看到自己的声音。
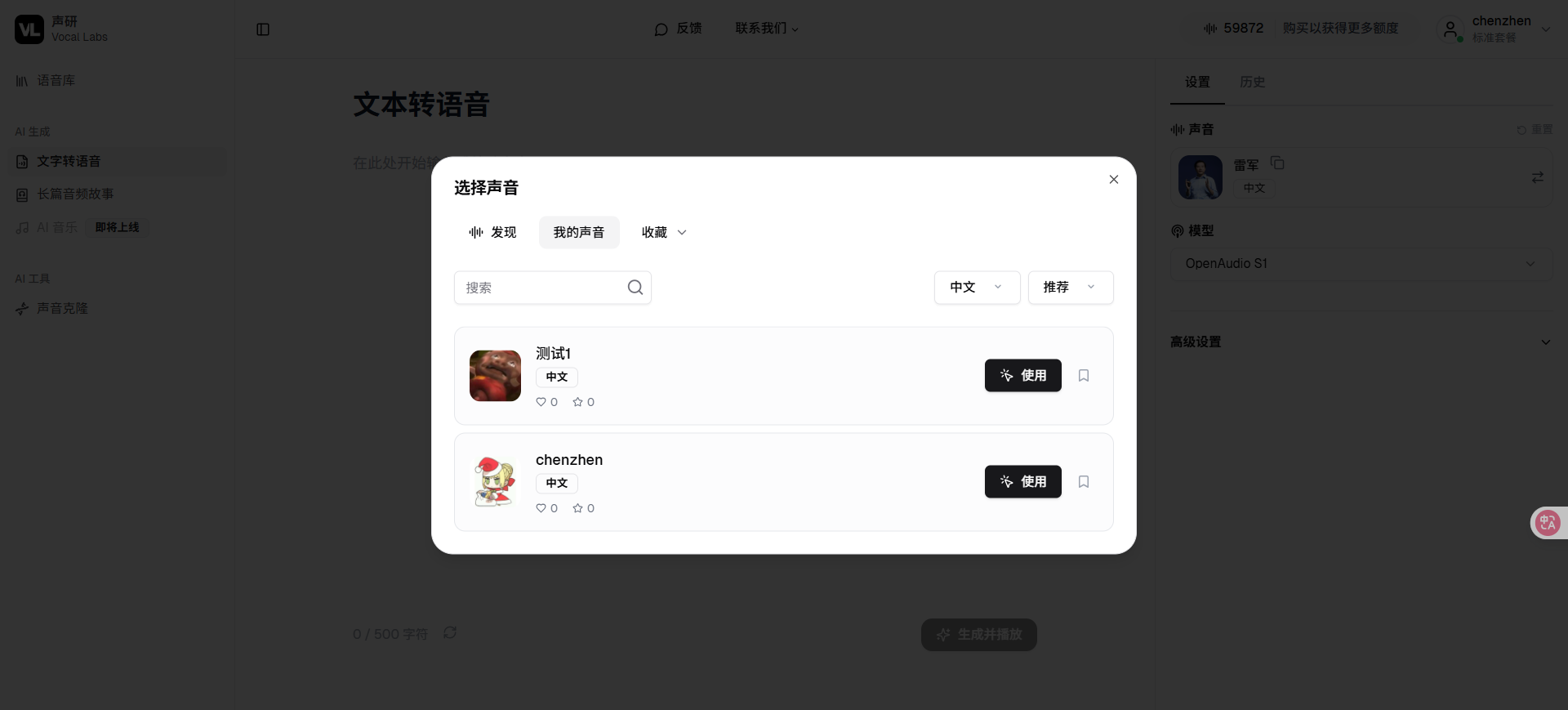
6️⃣ 然后你就可以直接在文字转语音页面选择我的声音去使用了!!!🎉🎉🎉
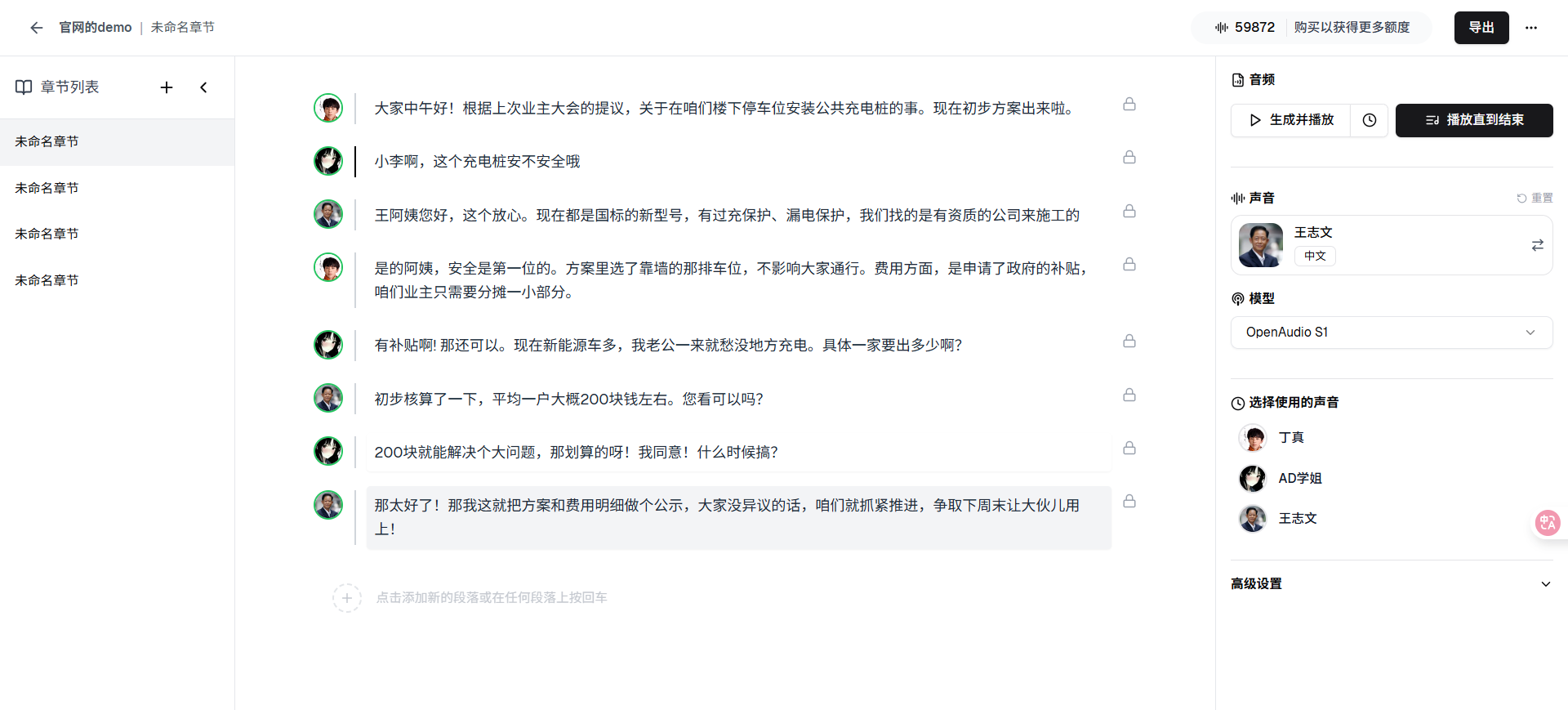
长篇音频故事(有声小说)
这个功能是专门用于生成和编辑长篇音频。可以一键将一本书生成有声读物。
官方地址:https://app.vocallabs.cn/studio
- 一键全文转换:这个功能允许用户点击一个按钮,将整个项目的文本内容转换为音频。
- 发言者分配:为不同的文本片段分配不同的声音。例如,在一部有声小说中,为每个角色分配一个独特的语音。
- 重新生成音频片段:如果用户对某个特定的音频片段不满意,他们可以选择重新生成它,而不会影响到整个音频的其他部分。
- 按章节划分:这个功能允许用户将文本内容分成多个部分或章节,这样他们可以更集中地处理每个部分,而不是整个文本。
- 保存和恢复进度:如果用户需要中断工作,他们可以保存他们的进度,并在以后的时间从他们停止的地方继续。
- 导入多种文件:这个功能允许用户直接导入常见的文件格式(如.epub、.pdf和.txt)或使用URL,这样他们可以更轻松地开始工作,而不需要进行额外的文件转换或复制粘贴。